Java 最细的集合类总结
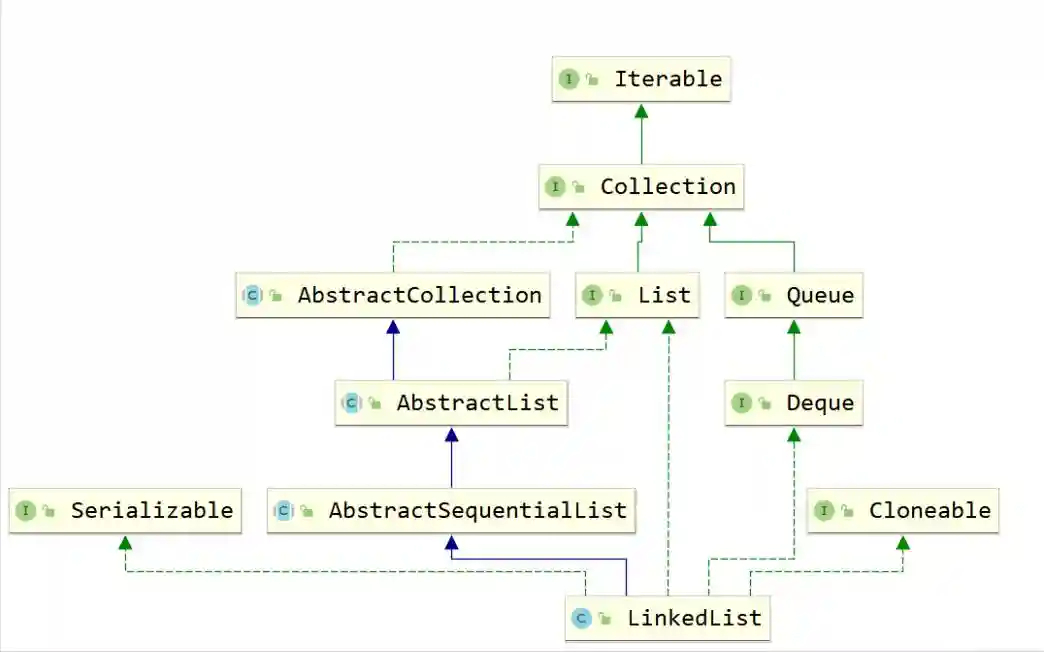
数据结构作为每一个开发者不可回避的问题,而Java对于不同的数据结构提供了非常成熟的实现,这一个又一个实现既是面试中的难点,也是工作中必不可少的工具,在此,笔者经历漫长的剖析,将其抽丝剥茧的呈现出来,在此仅作抛砖引玉,望得诸君高见,若君能有所获则在下甚是不亦乐乎,若有疑惑亦愿与诸君共求之!本文一共3.5W字,25张图,预计阅读2h。可以收藏这篇文章,用的时候防止找不到,这可能是你能看到的最详细的一篇文章了。 Java整个集合框架如上图所示(这儿不包括Map,Map的结构将放在集合后边进行讲述),可见所有集合实现类的最顶层接口为Iterable和Collection接口,再向下Collection分为了三种不同的形式,分别是List,Queue和Set接口,然后就是对应的不同的实现方式。 Iterable接口中只有iterator()一个接口方法,Iterator也是一个接口,其主要有如下两个方法hasNext()和next()方法。 可见Collection的主要接口方法有: List表示一串有序的集合,和Collection接口含义不同的是List突出有序的含义。 可见List其实比Collection多了添加方法add和addAll查找方法get,indexOf,set等方法,并且支持index下标操作。 Collection与List的区别? a.从上边可以看出Collection和List最大的区别就是Collection是无序的,不支持索引操作,而List是有序的。Collection没有顺序的概念。 中Iterator为ListIterator。 c.由a推导List可以进行排序,所以List接口支持使用sort方法。 d.二者的Spliterator操作方式不一样。 为什么子类接口里重复申明父类接口呢? 官方解释:在子接口中重复声明父接口是为了方便看文档。比如在javadoc文档里,在List接口里也能看到Collecion声明的相关接口。 ArrayList是List接口最常用的一个实现类,支持List接口的一些列操作。 2.2.1ArrayList继承关系 2.2.2ArrayList组成 一定要记住ArrayList中的transientObject[]elementData,该elementData是真正存放元素的容器,可见ArrayList是基于数组实现的。 2.2.3ArrayList构造函数 Object[]elementData是ArrayList真正存放数据的数组。 ArrayList支持默认大小构造,和空构造,当空构造的时候存放数据的Object[]elementData是一个空数组{}。 2.2.4ArrayList中添加元素 注意ArrayList中有一个modCount的属性,表示该实例修改的次数。(所有集合中都有modCount这样一个记录修改次数的属性),每次增改添加都会增加一次该ArrayList修改次数,而上边的add(Ee)方法是将新元素添加到list尾部。 2.2.5ArrayList扩容 可见当初始化的list是一个空ArrayList的时候,会直接扩容到DEFAULT_CAPACITY,该值大小是一个默认值10。而当添加进ArrayList中的元素超过了数组能存放的最大值就会进行扩容。注意到这一行代码 采用右移运算,就是原来的一般,所以是扩容1.5倍。 比如10的二进制是1010,右移后变成101就是5。 2.2.6数组copy Java是无法自己分配空间的,是底层C和C++的实现。以C为例,我们知道C中数组是一个指向首部的指针,比如我们C语言对数组进行分配内存。Java就是通过arraycopy这个native方法实现的数组的复制。 这样的好处何在呢? Java里内存是由jvm管理的,而数组是分配的连续内存,而arrayList不一定是连续内存,当然jvm会帮我们做这样的事,jvm会有内部的优化,会在后续的例子中结合问题来说明。 2.2.7why?elementData用transient修饰? transient的作用是该属性不参与序列化。 ArrayList继承了标示序列化的Serializable接口 对arrayList序列化的过程中进行了读写安全控制。 是如何实现序列化安全的呢? 在序列化方法writeObject()方法中可以看到,先用默认写方法,然后将size写出,最后遍历写出elementData,因为该变量是transient修饰的,所有进行手动写出,这样它也会被序列化了。那是不是多此一举呢? 当然不是,其中有一个关键的modCount,该变量是记录list修改的次数的,当写入完之后如果发现修改次数和开始序列化前不一致就会抛出异常,序列化失败。这样就保证了序列化过程中是未经修改的数据,保证了序列化安全。(java集合中都是这样实现) 众所周知LinkedList是一种链表结构,那么Java里LinkedList是如何实现的呢? 2.3.1LinkedList继承关系 可见LinkedList既是List接口的实现也是Queue的实现(Deque),故其和ArrayList相比LinkedList支持的功能更多,其可视作队列来使用,当然下文中不强调其队列的实现。 2.3.2LinkedList的结构 LinkedList由一个头节点和一个尾节点组成,分别指向链表的头部和尾部。 LinkedList中Node源码如下,由当前值item,和指向上一个节点prev和指向下个节点next的指针组成。并且只含有一个构造方法,按照(prev,item,next)这样的参数顺序构造。 那LinkedList里节点Node是什么结构呢? LinkedList由一个头节点,一个尾节点和一个默认为0的size构成,可见其是双向链表。 数据结构中链表的头插法linkFirst和尾插法linkLast 2.3.3LinkedList查询方法 按照下标获取某一个节点:get方法,获取第index个节点。 node(index)方法是怎么实现的呢? 判断index是更靠近头部还是尾部,靠近哪段从哪段遍历获取值。 查询索引修改方法,先找到对应节点,将新的值替换掉老的值。 这个也是为什么ArrayList随机访问比LinkedList快的原因,LinkedList要遍历找到该位置才能进行修改,而ArrayList是内部数组操作会更快。 2.3.4LinkedList修改方法 新增一个节点,可以看到是采用尾插法将新节点放入尾部。 和ArrayList一样,Vector也是List接口的一个实现类。其中List接口主要实现类有ArrayLIst,LinkedList,Vector,Stack,其中后两者用的特别少。 2.5.1vector组成 和ArrayList基本一样。 2.5.2vector线程安全性 vector是线程安全的,synchronized修饰的操作方法。 2.5.3vector扩容 看源码可知,扩容当构造没有capacityIncrement时,一次扩容数组变成原来两倍,否则每次增加capacityIncrement。 2.5.4vector方法经典示例 移除某一元素 这儿主要有一个两行代码需要注意,笔者在代码中有注释。数组移除某一元素并且移动后,一定要将原来末尾设为null,且有效长度减1。总体上vector实现是比较简单粗暴的,也很少用到,随便看看即可。 Stack也是List接口的实现类之一,和Vector一样,因为性能原因,更主要在开发过程中很少用到栈这种数据结构,不过栈在计算机底层是一种非常重要的数据结构,下边将探讨下Java中Stack。 2.6.1Stack的继承关系 Stack继承于Vector,其也是List接口的实现类。之前提到过Vector是线程安全的,因为其方法都是synchronized修饰的,故此处Stack从父类Vector继承而来的操作也是线程安全的。 2.6.2Stack的使用 正如Stack是栈的实现,故其主要操作为push入栈和pop出栈,而栈最大的特点就是LIFO(LastInFirstOut)。 上边代码可以看到,最后push入栈的字符串"ccc"也最先出栈。 2.6.3Stack源码 从Stack的源码中可见,其用的push方法用的是Vector的addElement(Ee)方法,该方法是将元素放在集合的尾部,而其pop方法使用的是Vector的removeElementAt(Indexx)方法,移除并获取集合的尾部元素,可见Stack的操作就是基于线性表的尾部进行操作的。 正如数据结构中描述,queue是一种先进先出的数据结构,也就是firstinfirstout。可以将queue看作一个只可以从某一段放元素进去的一个容器,取元素只能从另一端取,整个机制如下图所示,不过需要注意的是,队列并没有规定是从哪一端插入,从哪一段取出。 Deque英文全称是Doubleedqueue,也就是俗称的双端队列。就是说对于这个队列容器,既可以从头部插入也可以从尾部插入,既可以从头部获取,也可以从尾部获取,其机制如下图所示。 3.3.1Java中的Queue接口 此处需要注意,Java中的队列明确有从尾部插入,头部取出,所以Java中queue的实现都是从头部取出。 Javaqueue常常使用的方法如表格所示,对于表格中接口和表格中没有的接口方法区别为:队列的操作不会因为队列为空抛出异常,而集合的操作是队列为空抛出异常。 3.1.2Deque接口 和Queue中的方法一样,方法名多了First或者Last,First结尾的方法即从头部进行操作,Last即从尾部进行操作。 3.1.3Queue,Deque的实现类 Java中关于Queue的实现主要用的是双端队列,毕竟操作更加方便自由,Queue的实现有PriorityQueue,Deque在中主要有ArrayDeque和LinkedList两个实现类,两者一个是基于数组的实现,一个是基于链表的实现。在之前LinkedList文章中也提到过其是一个双向链表,在此基础之上实现了Deque接口。 PriorityQueue是Java中唯一一个Queue接口的直接实现,如其名字所示,优先队列,其内部支持按照一定的规则对内部元素进行排序。 3.2.1PriorityQueue继承关系 先看下PriorityQueue的继承实现关系,可知其是Queue的实现类,主要使用方式是队列的基本操作,而之前讲到过Queue的基本原理,其核心是FIFO(FirstInFirstOut)原理。 Java中的PriorityQueue的实现也是符合队列的方式,不过又略有不同,却别就在于PriorityQueue的priority上,其是一个支持优先级的队列,当使用了其priority的特性的时候,则并非FIFO。 3.2.2PriorityQueue的使用 案列1: 上述代码做的事为往队列中放入10个int值,然后使用Queue的poll()方法依次取出,最后结果为每次取出来都是队列中最小的值,说明 了PriorityQueue内部确实是有一定顺序规则的。 案例2: 上述代码重写了compareTo方法都返回0,即不做优先级排序。发现我们返回的顺序为Test{a=20}-Test{a=15}-Test{a=12}-Test{a=10}-Test{a=13}-Test{a=11}-Test{a=9}-Test{a=8}-Test{a=21}-Test{a=14},和放入的顺序还是不同,所以这儿需要注意在实现Comparable接口的时候一定要按照一定的规则进行优先级排序,关于为什么取出来的顺序和放入的顺序不一致后边将从源码来分析。 3.2.3PriorityQueue组成 可以看到PriorityQueue的组成很简单,主要记住一个存放元素的数组,和一个Comparator比较器即可。 3.2.4PriorityQueue操作方法 offer方法 首先可以看到当Queue中为空的时候,第一次放入的元素直接放在了数组的第一位,那么上边案例二中第一个放入的20就在数组的第一位。而当queue中不为空时,又使用siftUp(i,e)方法,传入的参数是队列中已有元素数量和即将要放入的新元素,现在就来看下究竟siftUp(i,e)做了什么事。 还记得上边提到PriorityQueue的组成,是一个存放元素的数组,和一个Comparator比较器。这儿是指当没有Comparator是使用元素类实现compareTo方法进行比较。其含义为优先使用自定义的比较规则Comparator,否则使用元素所在类实现的Comparable接口方法。 可以看到,当PriorityQueue不为空时插入一个新元素,会对其新元素进行堆排序处理(对于堆排序此处不做描述),这样每次进来都会对该元素进行堆排序运算,这样也就保证了Queue中第一个元素永远是最小的(默认规则排序)。 pool方法 此处可知,当取出一个值进行了siftDown操作,传入的参数为索引0和队列中的最后一个元素。 当没有Comparator比较器是采用的siftDown方法如上,因为索引0位置取出了,找索引0的子节点比它小的作为新的父节点并在循环内递归。PriorityQueue是不是很简单呢,其他细节就不再详解,待诸君深入。 ArrayDeque是Java中基于数组实现的双端队列,在Java中Deque的实现有LinkedList和ArrayDeque,正如它两的名字就标志了它们的不同,LinkedList是基于双向链表实现的,而ArrayDeque是基于数组实现的。 3.3.1ArrayDeque的继承关系 可见ArrayDeque是Deque接口的实现,和LinkedList不同的是,LinkedList既是List接口也是Deque接口的实现。 3.3.2ArrayDeque使用 案列 案例二: 上述程序最后得到队列中排列结果为ccc,aaa,bbb,ddd所以循环使用**pollLast(),**ddd,bbb,aaa,ccc,图示案列二的插入逻辑如下: 3.3.4ArrayDeque内部组成 3.3.5数组elements长度 此处elements数组的长度永远是2的幂次方,此处的实现方法和hashMap中基本一样,即保证长度的二进制全部由1组成,然后再加1,则变成了100…,故一定是2的幂次方。 3.3.6ArrayDeque实现机制 如下图所示: 此处应将数组视作首尾相连的,最初头部和尾部索引都是0,addLast方向往右,addFirst方向往左,所以数组中间可能是空的,当头指针和尾指针相遇的时候对数组进行扩容,并对元素位置进行调整。 源码: 注意下边这行代码,表示当head-1大于等于0时,head=head-1,否则head=。 换一种写法就是下边这样,是不是就是上边addFirst的指针移动方向? 这个就是位运算的神奇操作了,因为任何数与大于它的一个全是二进制1做运算时等于它自身,如10101111=1010,此处不赘述。 再看addLast方法: 同样的注意有一串神奇代码。 该表达式等于tail=tail+1element-1?0:tail+1,是不是很神奇的写法,其原理是一个二进制数全部由1组成和一个大于它的数做运算结果为0,如100001111=0。poll方法和add方法逻辑是相反的,此处就不再赘述,诸君共求之! 如果说List对集合加了有序性的化,那么Set就是对集合加上了唯一性。 java中的Set接口和Colletion是完全一样的定义。 Java中的HashSet如其名字所示,其是一种Hash实现的集合,使用的底层结构是HashMap。 4.2.1HashSet继承关系 4.2.2HashSet源码 可以看到HashSet内部其实是一个HashMap。 4.2.3HashSet是如何保证不重复的呢? 可见HashSet的add方法,插入的值会作为HashMap的key,所以是HashMap保证了不重复。map的put方法新增一个原来不存在的值会返回null,如果原来存在的话会返回原来存在的值。 关于HashMap是如何实现的,见后续! LinkedHashSet用的也比较少,其也是基于Set的实现。 4.3.1LinkedHashSet继承关系 和HashSet一样,其也是Set接口的实现类,并且是HashSet的子类。 4.3.2LinkedHashSet源码 其操作方法和HashSet完全一样,那么二者区别是什么呢? 1.首先LinkedHashSet是HashSet的子类。2.LinkedHashSet中用于存储值的实现LinkedHashMap,而HashSet使用的是HashMap。LinkedHashSet中调用的父类构造器,可以看到其实列是一个LinkedHashMap。 LinkedHashSet的实现很简单,更深入的了解需要去看LinkedHashMap的实现,对LinkedHashMap的解析将单独提出。 Map是一种键值对的结构,就是常说的Key-Value结构,一个Map就是很多这样K-V键值对组成的,一个K-V结构我们将其称作Entry,在Java里,Map是用的非常多的一种数据结构。上图展示了Map家族最基础的一个结构(只是指中)。 Map接口本身就是一个顶层接口,由一堆Map自身接口方法和一个Entry接口组成,Entry接口定义了主要是关于Key-Value自身的一些操作,Map接口定义的是一些属性和关于属性查找修改的一些接口方法。 HashMap是Java中最常用K-V容器,采用了哈希的方式进行实现,HashMap中存储的是一个又一个Key-Value的键值对,我们将其称作Entry,HashMap对Entry进行了扩展(称作Node),使其成为链表或者树的结构使其存储在HashMap的容器里(是一个数组)。 5.2.1HashMap继承关系 5.2.2HashMap存储的数据 Map接口中有一个Entry接口,在HashMap中对其进行了实现,Entry的实现是HashMap存放的数据的类型。其中Entry在HashMap的实现是Node,Node是一个单链表的结构,TreeNode是其子类,是一个红黑树的类型,其继承结构图如下: HashMap存放数据的数据是什么呢?代码中存放数据的容器如下: 说明了该容器中是一个又一个node组成,而node有三种实现,所以hashMap中存放的node的形式既可以是Node也可以是TreeNode。 5.2.3HashMap的组成 有了上边的概念之后来看一下HashMap里有哪些组成吧! 这儿要说两个概念,table是指的存放数据的数组,bin是指的table中某一个位置的node,一个node可以理解成一批/一盒数据。 5.2.4HashMap中的构造函数 该方法将一个二进制数第一位1后边的数字全部变成1,然后再加1,这样这个二进制数就一定是100…这样的形式。此处实现在ArrayDeque的实现中也用到了类似的方法来保证数组长度一定是2的幂次方。 5.2.5put方法 开发人员使用的put方法: 真正HashMap内部使用的put值的方法: 5.2.6查找方法 和HashMap不同,HashTable的实现方式完全不同,这点从二者的类继承关系就可以看出端倪来,HashTable和HashMap虽然都实现了Map接口,但是HashTable继承了DIctionary抽象类,而HashMap继承了AbstractMap抽象类。 5.3.1HashTable的类继承关系图 HashTable HashMap 5.3.2Dictionary接口 Dictionary类中有这样一行注释,当key为null时会抛出空指针NullPointerException,这也说明了HashTabel是不允许Key为null的。 5.3.3HashTable组成 HashTable中的元素存在Entry?,?[]table中,是一个Entry数组,Entry是存放的节点,每一个Entry是一个链表。 5.3.4HashTable中的Entry 知道Entry是一个单链表即可,和HashMap中的Node结构相同,但是HashMap中还有Node的子类TreeNode。 5.3.5put方法 本质上就是先hash求索引,遍历该索引Entry链表,如果找到hash值和key都和put的key一样的时候就替换旧值,否则使用addEntry方法添加新值进入table,因为添加新元素就涉及到修改元素大小,还可能需要扩容等,具体看下边的addEntry方法可知。 这行代码是真正插入新元素的方法,采用头插法,单链表一般都用头插法(快)。 5.3.6get方法 get方法就简单很多就是hash,找到索引,遍历链表找到对应的value,没有则返回null。相比诸君都已经看到,HashTable中方法是用synchronized修饰的,所以其操作是线程安全的,但是效率会受影响。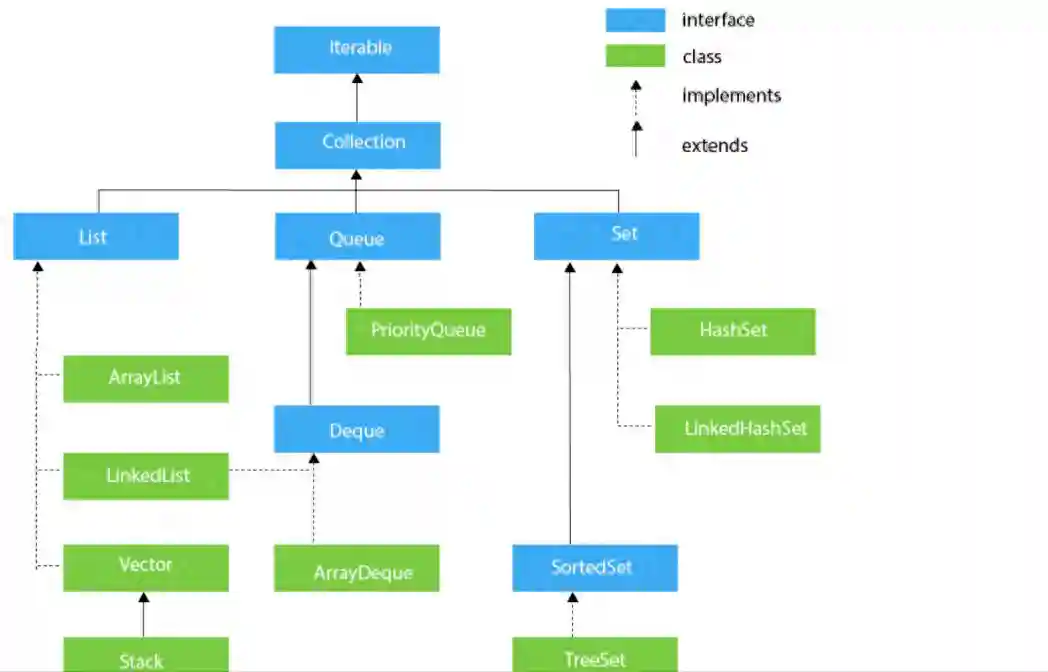
//支持lambda函数接口;publicinterfaceIterableT{//iterator()方法IteratorTiterator();defaultvoidforEach(Consumer?superTaction){(action);for(Tt:this){(t);}}defaultSpliteratorTspliterator(){(iterator(),0);}};;;;publicinterfaceCollectionEextsIterableE{intsize();booleanisEmpty();booleancontains(Objecto);IteratorEiterator();Object[]toArray();booleanadd(Ee);booleanremove(Objecto);booleancontainsAll(Collection?c);booleanremoveAll(Collection?c);defaultbooleanremoveIf(Predicate?superEfilter){(filter);booleanremoved=false;finalIteratorEeach=iterator();while(()){if((())){();removed=true;}}returnremoved;}booleanretainAll(Collection?c);voidclear();inthashCode();@OverridedefaultSpliteratorEspliterator(){(this,0);}defaultStreamEstream(){(spliterator(),false);}defaultStreamEparallelStream(){(spliterator(),true);}}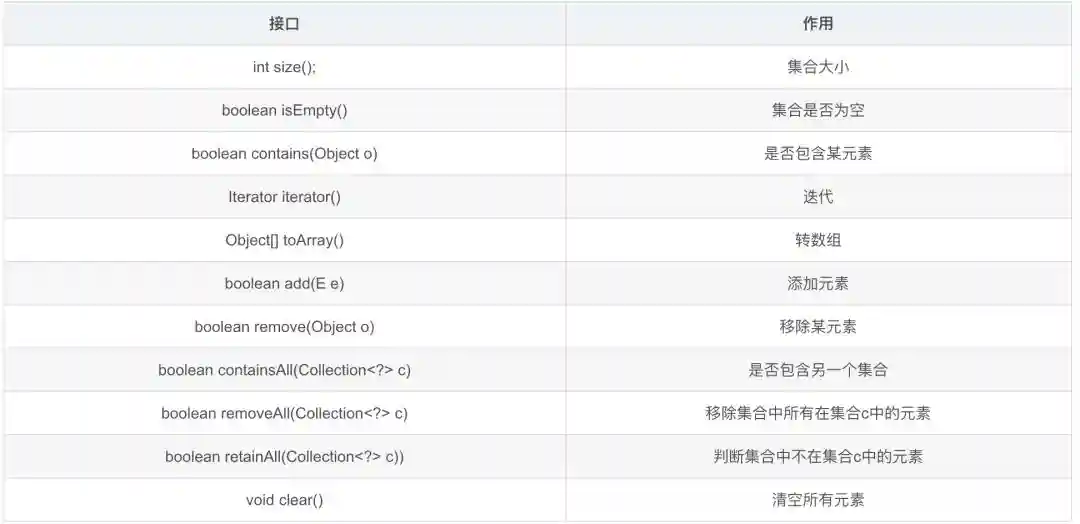
;;publicinterfaceListEextsCollectionE{TT[]toArray(T[]a);booleanaddAll(Collection?extsEc);booleanaddAll(intindex,Collection?extsEc);defaultvoidreplaceAll(UnaryOperatorEoperator){(operator);finalListIteratorEli=();while(()){((()));}}defaultvoidsort(Comparator?superEc){Object[]a=();(a,(Comparator)c);ListIteratorEi=();for(Objecte:a){();((E)e);}}booleanequals(Objecto);Eget(intindex);Eset(intindex,Eelement);voidadd(intindex,Eelement);intindexOf(Objecto);intlastIndexOf(Objecto);ListIteratorElistIterator();ListEsubList(intfromIndex,inttoIndex);@OverridedefaultSpliteratorEspliterator(){(this,);}}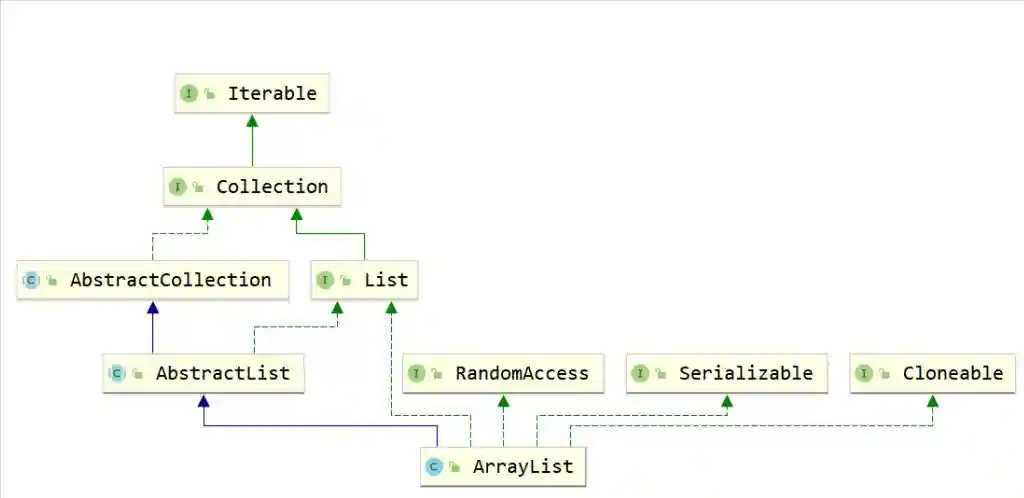
privatestaticfinalObject[]EMPTY_ELEMENTDATA={};privatestaticfinalObject[]DEFAULTCAPACITY_EMPTY_ELEMENTDATA={}//真正存放元素的数组transientObject[]elementData;//non-privatetosimplifynestedclassaccessprivateintsize;publicArrayList(intinitialCapacity){if(initialCapacity0){=newObject[initialCapacity];}elseif(initialCapacity==0){=EMPTY_ELEMENTDATA;}else{thrownewIllegalArgumentException("IllegalCapacity:"+initialCapacity);}}publicArrayList(){=DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}publicbooleanadd(Ee){ensureCapacityInternal(size+1);//IncrementsmodCount!!elementData[size++]=e;returntrue;}privatestaticintcalculateCapacity(Object[]elementData,intminCapacity){if(elementData==DEFAULTCAPACITY_EMPTY_ELEMENTDATA){//DEFAULT_CAPACITY是10(DEFAULT_CAPACITY,minCapacity);}returnminCapacity;}intnewCapacity=oldCapacity+(oldCapacity1);
privatevoidgrow(intminCapacity){//overflow-consciouscodeintoldCapacity=;intnewCapacity=oldCapacity+(oldCapacity1);if(newCapacity-minCapacity0)newCapacity=minCapacity;if(newCapacity-MAX_ARRAY_SIZE0)newCapacity=hugeCapacity(minCapacity);//minCapacityisusuallyclosetosize,sothisisawin:elementData=(elementData,newCapacity);}publicstaticnativevoidarraycopy(Objectsrc,intsrcPos,Objectdest,intdestPos,intlength);
p=(int*)malloc(len*sizeof(int));
privatevoidwriteObject(){//Writeoutelementcount,andanyhiddenstuffintexpectedModCount=modCount;();//Writeoutsizeascapacityforbehaviouralcompatibilitywithclone()(size);//(inti=0;isize;i++){(elementData[i]);}if(modCount!=expectedModCount){thrownewConcurrentModificationException();}}/***ReconstitutethettArrayList/ttinstancefromastream(thatis,*deserializeit).*/privatevoidreadObject(),ClassNotFoundException{elementData=EMPTY_ELEMENTDATA;//Readinsize,();//();//ignoredif(size0){//belikeclone(),allocatearraybaseduponsizenotcapacityintcapacity=calculateCapacity(elementData,size);().checkArray(s,Object[].class,capacity);ensureCapacityInternal(size);Object[]a=elementData;//(inti=0;isize;i++){a[i]=();}}}protectedtransientintmodCount=0;
transientNodeEfirst;/***Pointertolastnode.*Invariant:(first==nulllast==null)||*(==!=null)*/transientNodeElast;
privatestaticclassNodeE{Eitem;NodeEnext;NodeEprev;Node(NodeEprev,Eelement,NodeEnext){=element;=next;=prev;}}transientintsize=0;transientNodeEfirst;transientNodeElast;publicLinkedList(){}/***Linkseasfirstelement.头插法*/privatevoidlinkFirst(Ee){finalNodeEf=first;finalNodeEnewNode=newNode(null,e,f);first=newNode;if(f==null)last=newNode;=newNode;size++;modCount++;}/***Linkseaslastelement.尾插法*/voidlinkLast(Ee){finalNodeEl=last;finalNodeEnewNode=newNode(l,e,null);last=newNode;if(l==null)first=newNode;=newNode;size++;modCount++;}publicEget(intindex){checkElementIndex(index);returnnode(index).item;}NodeEnode(intindex){//assertisElementIndex(index);//判断index更靠近头部还是尾部if(index(size1)){NodeEx=first;for(inti=0;iindex;i++)x=;returnx;}else{NodeEx=last;for(inti=size-1;iindex;i--)x=;returnx;}}publicEset(intindex,Eelement){checkElementIndex(index);NodeEx=node(index);EoldVal=;=element;returnoldVal;}publicbooleanadd(Ee){linkLast(e);returntrue;}2.5Vector//存放元素的数组protectedObject[]elementData;//有效元素数量,小于等于数组长度protectedintelementCount;//容量增加量,和扩容相关protectedintcapacityIncrement;
privatevoidgrow(intminCapacity){//overflow-consciouscodeintoldCapacity=;//扩容大小intnewCapacity=oldCapacity+((capacityIncrement0)?capacityIncrement:oldCapacity);if(newCapacity-minCapacity0)newCapacity=minCapacity;if(newCapacity-MAX_ARRAY_SIZE0)newCapacity=hugeCapacity(minCapacity);elementData=(elementData,newCapacity);}publicsynchronizedEremove(intindex){modCount++;if(index=elementCount)thrownewArrayIndexOutOfBoundsException(index);EoldValue=elementData(index);intnumMoved=elementCount-index-1;if(numMoved0)//复制数组,假设数组移除了中间某元素,后边有效值前移1位(elementData,index+1,elementData,index,numMoved);//引用null,gc会处理elementData[--elementCount]=null;//LetgcdoitsworkreturnoldValue;}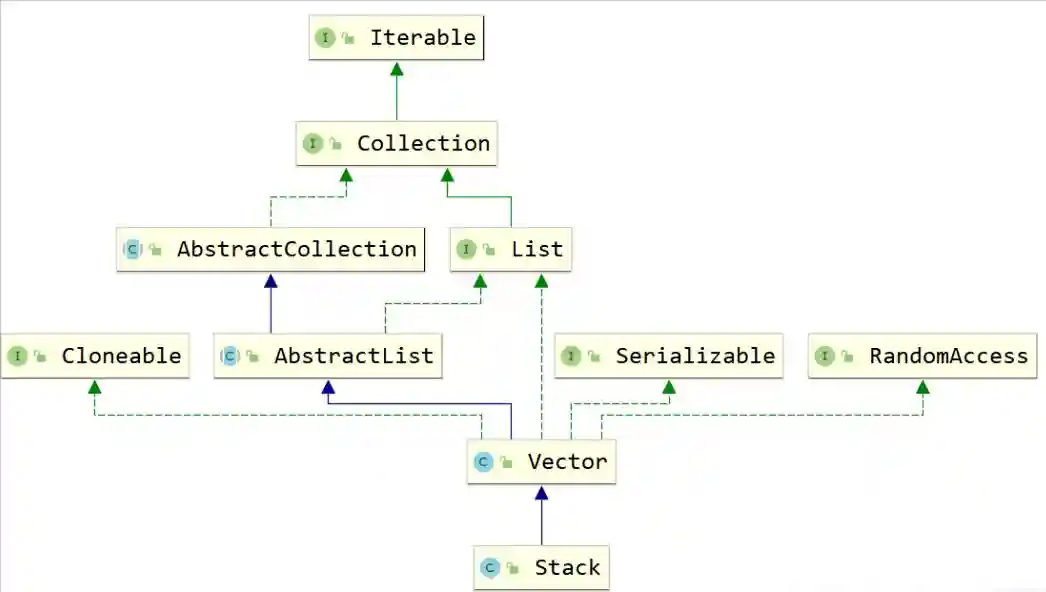
StackStringstrings=newStack();("aaa");("bbb");("ccc");(());
/***Stack源码(Jdk8)*/publicclassStackEextsVectorE{publicStack(){}//入栈,使用的是Vector的addElement方法。publicEpush(Eitem){addElement(item);returnitem;}//出栈,找到数组最后一个元素,移除并返回。publicsynchronizedEpop(){Eobj;intlen=size();obj=peek();removeElementAt(len-1);returnobj;}publicsynchronizedEpeek(){intlen=size();if(len==0)thrownewEmptyStackException();returnelementAt(len-1);}publicbooleanempty(){returnsize()==0;}publicsynchronizedintsearch(Objecto){inti=lastIndexOf(o);if(i=0){returnsize()-i;}return-1;}privatestaticfinallongserialVersionUID=1224463164541339165L;}

;publicinterfaceQueueEextsCollectionE{//集合中插入元素booleanadd(Ee);//队列中插入元素booleanoffer(Ee);//移除元素,当集合为空,抛出异常Eremove();//移除队列头部元素并返回,如果为空,返回nullEpoll();//查询集合第一个元素,如果为空,抛出异常Eelement();//查询队列中第一个元素,如果为空,返回nullEpeek();}
;publicinterfaceDequeEextsQueueE{//deque的操作方法voidaddFirst(Ee);voidaddLast(Ee);booleanofferFirst(Ee);booleanofferLast(Ee);EremoveFirst();EremoveLast();EpollFirst();EpollLast();EgetFirst();EgetLast();EpeekFirst();EpeekLast();booleanremoveFirstOccurrence(Objecto);booleanremoveLastOccurrence(Objecto);//***Queuemethods***booleanadd(Ee);booleanoffer(Ee);Eremove();Epoll();Eelement();Epeek();//省略一堆stack接口方法和collection接口方法}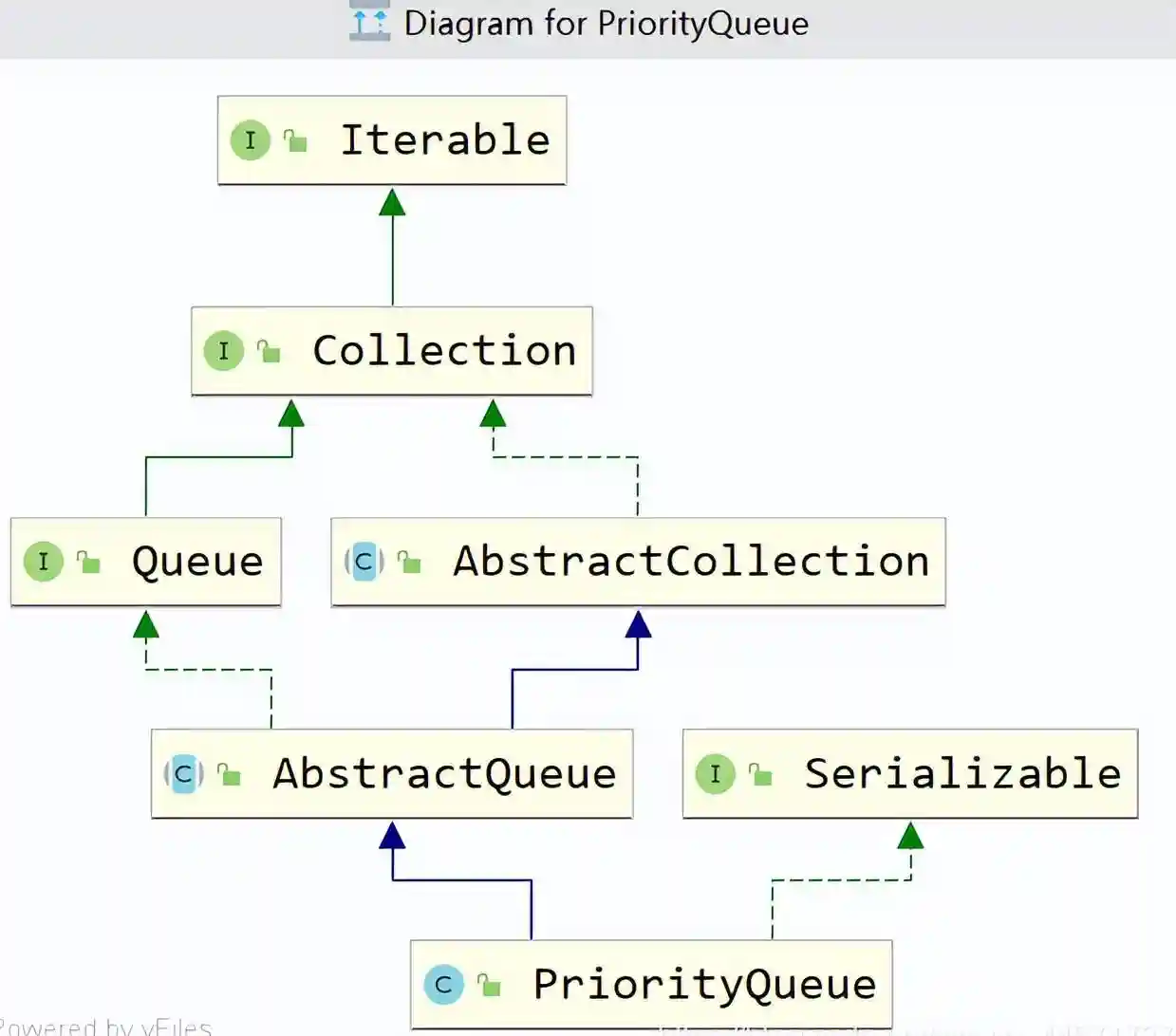
PriorityQueueIntegerqueue=newPriorityQueue();(20);(14);(21);(8);(9);(11);(13);(10);(12);(15);while(()0){Integerpoll=();(poll+"-");}
//必须实现Comparable方法,想String,数值本身即可比较privatestaticclassTestimplementsComparableTest{privateinta;publicTest(inta){=a;}publicintgetA(){returna;}publicvoidsetA(inta){=a;}@OverridepublicStringtoString(){return"Test{"+"a="+a+'}';}@OverridepublicintcompareTo(Testo){return0;}}publicstaticvoidmain(String[]args){PriorityQueueTestqueue=newPriorityQueue();(newTest(20));(newTest(14));(newTest(21));(newTest(8));(newTest(9));(newTest(11));(newTest(13));(newTest(10));(newTest(12));(newTest(15));while(()0){Testpoll=();(poll+"-");}}
/***默认容量大小,数组大小*/privatestaticfinalintDEFAULT_INITIAL_CAPACITY=11;/***存放元素的数组*/transientObject[]queue;//non-privatetosimplifynestedclassaccess/***队列中存放了多少元素*/privateintsize=0;/***自定义的比较规则,有该规则时优先使用,否则使用元素实现的Comparable接口方法。*/privatefinalComparator?superEcomparator;/***队列修改次数,每次存取都算一次修改*/transientintmodCount=0;//non-privatetosimplifynestedclassaccess
publicbooleanoffer(Ee){if(e==null)thrownewNullPointerException();modCount++;inti=size;if(i=)grow(i+1);size=i+1;//i=size,当queue为空的时候if(i==0)queue[0]=e;elsesiftUp(i,e);returntrue;}privatevoidsiftUp(intk,Ex){if(comparator!=null)siftUpUsingComparator(k,x);elsesiftUpComparable(k,x);}privatevoidsiftUpComparable(intk,Ex){Comparable?superEkey=(Comparable?superE)x;while(k0){//为什么-1,思考数组位置0,1,2。0是1和2的父节点intparent=(k-1)1;//父节点Objecte=queue[parent];//当传入的新节点大于父节点则不做处理,否则二者交换if(((E)e)=0)break;queue[k]=e;k=parent;}queue[k]=key;}publicEpoll(){if(size==0)returnnull;ints=--size;modCount++;Eresult=(E)queue[0];//s=--size,即原来数组的最后一个元素Ex=(E)queue[s];queue[s]=null;if(s!=0)siftDown(0,x);returnresult;}privatevoidsiftDownComparable(intk,Ex){Comparable?superEkey=(Comparable?superE)x;inthalf=size1;//loopwhileanon-leafwhile(khalf){intchild=(k1)+1;//assumeleftchildisleastObjectc=queue[child];intright=child+1;if(rightsize//c和right是parent的两个子节点,找出小的那个成为新的c。((Comparable?superE)c).compareTo((E)queue[right])0)c=queue[child=right];if(((E)c)=0)break;//小的变成了新的父节点queue[k]=c;k=child;}queue[k]=key;}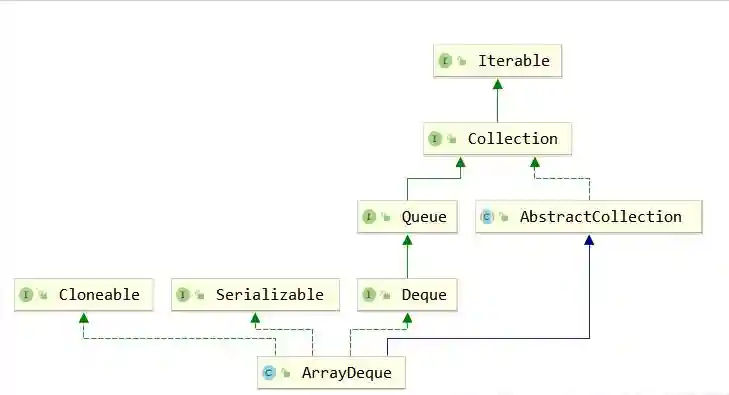
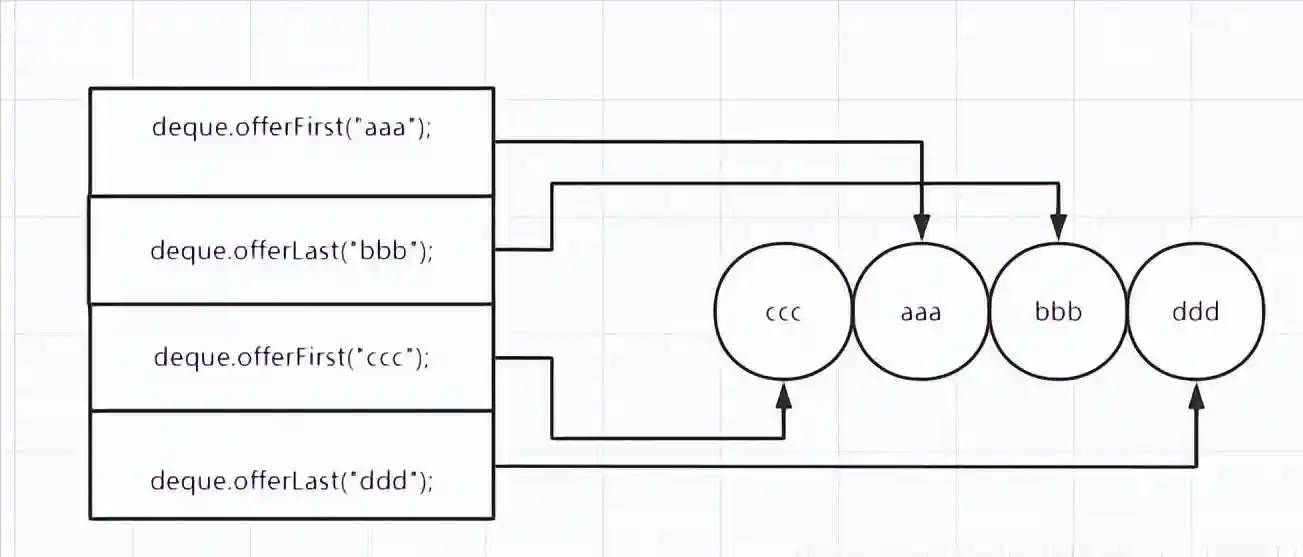
ArrayDequeStringdeque=newArrayDeque();("aaa");("bbb");("ccc");("ddd");//peek方法只获取不移除(());(());
ArrayDequeStringdeque=newArrayDeque();("aaa");("bbb");("ccc");("ddd");Stringa;while((a=())!=null){(a+"-");}
//具体存放元素的数组,数组大小一定是2的幂次方transientObject[]elements;//non-privateto//队列头索引transientinthead;//队列尾索引transientinttail;//默认的最小初始化容量,即传入的容量小于8容量为8,而默认容量是16privatestaticfinalintMIN_INITIAL_CAPACITY=8;
privatestaticintcalculateSize(intnumElements){intinitialCapacity=MIN_INITIAL_CAPACITY;//Findthebestpoweroftwotoholdelements.//Tests"="becausearraysaren'(numElements=initialCapacity){initialCapacity=numElements;initialCapacity|=(initialCapacity1);initialCapacity|=(initialCapacity2);initialCapacity|=(initialCapacity4);initialCapacity|=(initialCapacity8);initialCapacity|=(initialCapacity16);initialCapacity++;if(initialCapacity0)//Toomanyelements,mustbackoffinitialCapacity=1;//Goodluckallocating2^30elements}returninitialCapacity;}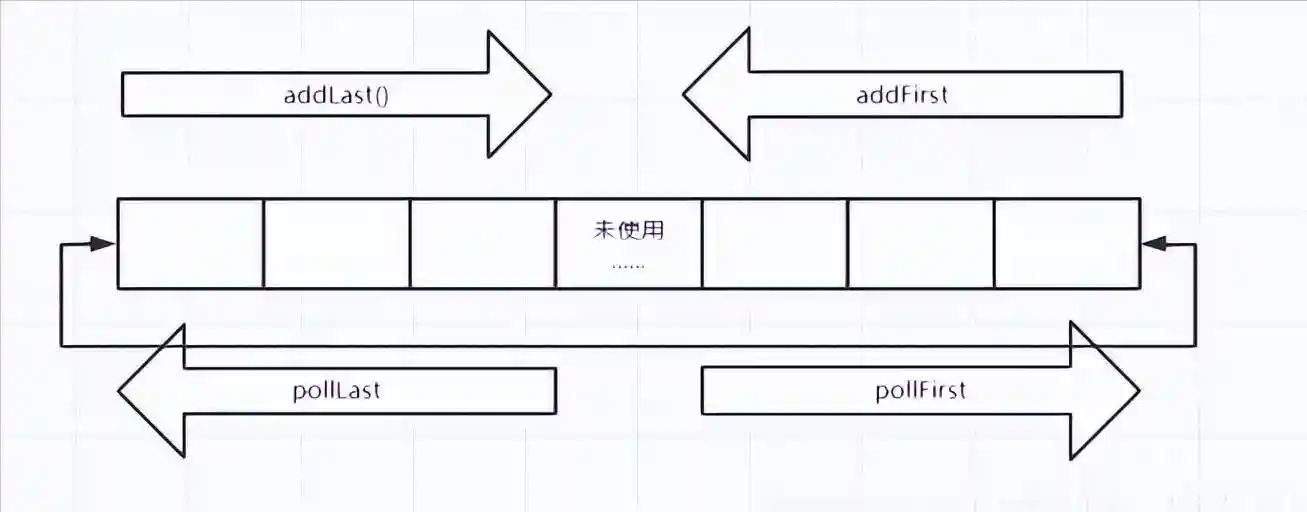
publicvoidaddFirst(Ee){if(e==null)thrownewNullPointerException();elements[head=(head-1)()]=e;if(head==tail)doubleCapacity();}head=(head-1)()
head=head-1=0?head-1:
publicvoidaddLast(Ee){if(e==null)thrownewNullPointerException();elements[tail]=e;if((tail=(tail+1)())==head)doubleCapacity();}(tail=(tail+1)())
;publicinterfaceSetEextsCollectionE{//QueryOperationsintsize();booleanisEmpty();Object[]toArray();TT[]toArray(T[]a);//ModificationOperationsbooleanadd(Ee);booleanremove(Objecto);booleancontainsAll(Collection?c);booleanaddAll(Collection?extsEc);booleanretainAll(Collection?c);booleanremoveAll(Collection?c);voidclear();booleanequals(Objecto);inthashCode();//此处和Collection接口由区别SpliteratorEspliterator(){(this,);}}4.2HashSet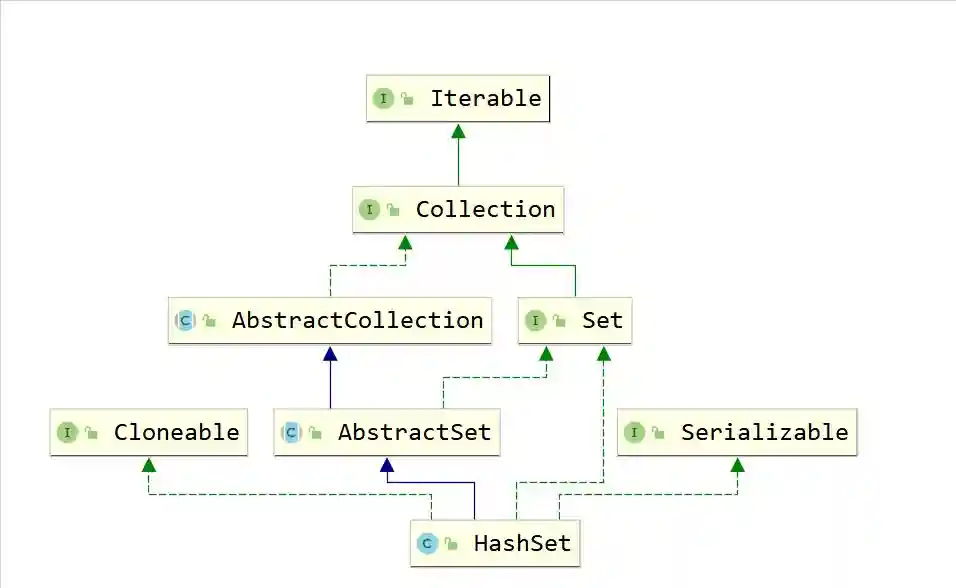
publicclassHashSetEextsAbstractSetEimplementsSetE,Cloneable,{staticfinallongserialVersionUID=-5024744406713321676L;privatetransientHashMapE,Objectmap;privatestaticfinalObjectPRESENT=newObject();publicHashSet(){map=newHashMap();}publicHashSet(Collection?extsEc){map=newHashMap(((int)(()/.75f)+1,16));addAll(c);}publicHashSet(intinitialCapacity,floatloadFactor){map=newHashMap(initialCapacity,loadFactor);}publicHashSet(intinitialCapacity){map=newHashMap(initialCapacity);}HashSet(intinitialCapacity,floatloadFactor,booleandummy){map=newLinkedHashMap(initialCapacity,loadFactor);}publicIteratorEiterator(){().iterator();}publicintsize(){();}publicbooleanisEmpty(){();}publicbooleancontains(Objecto){(o);}publicbooleanadd(Ee){(e,PRESENT)==null;}publicbooleanremove(Objecto){(o)==PRESENT;}publicvoidclear(){();}}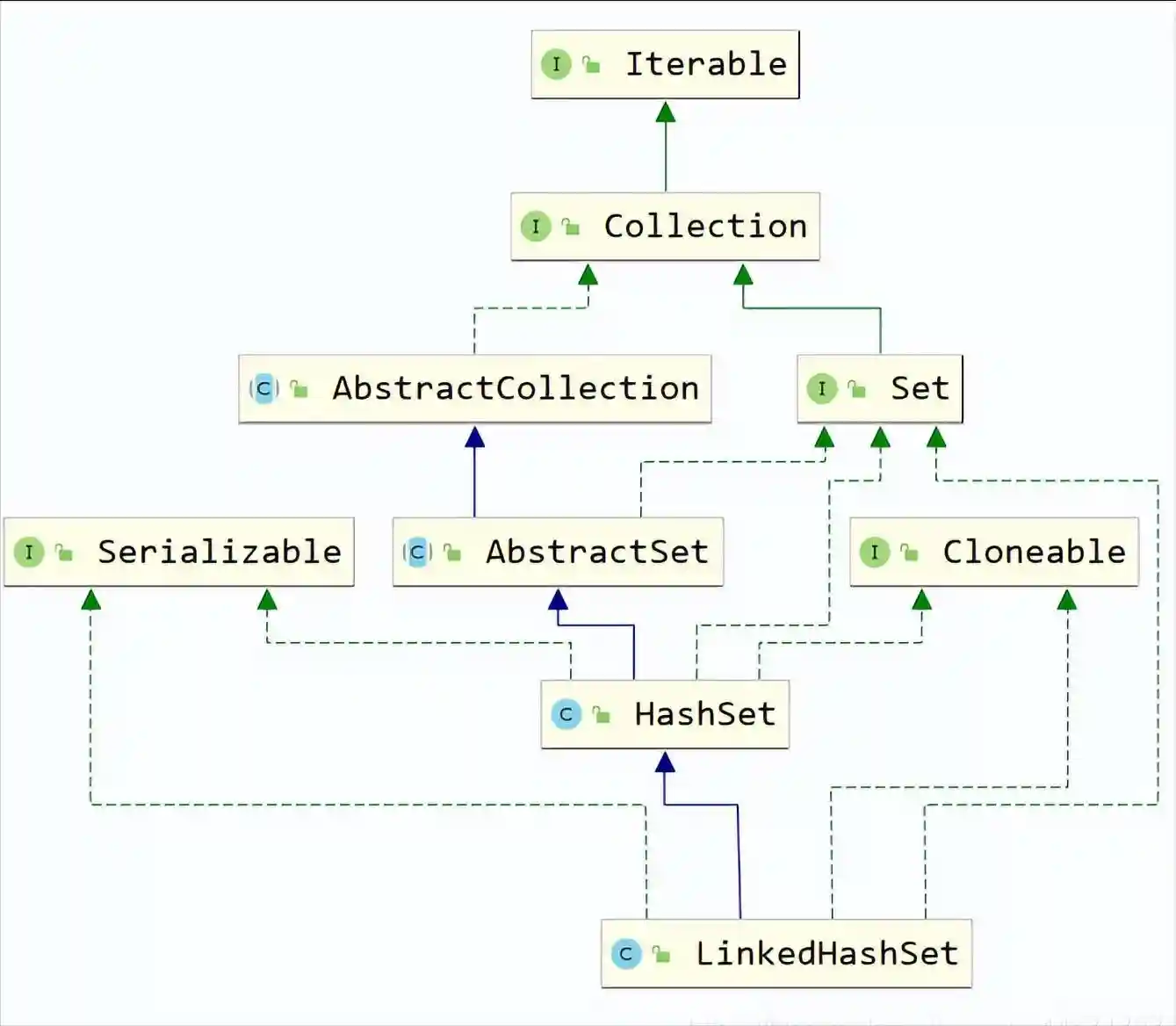
;publicclassLinkedHashSetEextsHashSetEimplementsSetE,Cloneable,{privatestaticfinallongserialVersionUID=-2851667679971038690L;publicLinkedHashSet(intinitialCapacity,floatloadFactor){//调用HashSet的构造方法super(initialCapacity,loadFactor,true);}publicLinkedHashSet(intinitialCapacity){super(initialCapacity,.75f,true);}publicLinkedHashSet(){super(16,.75f,true);}publicLinkedHashSet(Collection?extsEc){super((2*(),11),.75f,true);addAll(c);}@OverridepublicSpliteratorEspliterator(){(this,|);}}HashSet(intinitialCapacity,floatloadFactor,booleandummy){map=newLinkedHashMap(initialCapacity,loadFactor);};;;;;publicinterfaceMapK,V{//QueryOperationsintsize();booleanisEmpty();booleancontainsKey(Objectkey);booleancontainsValue(Objectvalue);Vget(Objectkey);//ModificationOperationsVput(Kkey,Vvalue);Vremove(Objectkey);//BulkOperationsvoidputAll(Map?extsK,?extsVm);voidclear();SetKkeySet();CollectionVvalues();,VentrySet();interfaceEntryK,V{KgetKey();VgetValue();VsetValue(Vvalue);booleanequals(Objecto);inthashCode();publicstaticKextsComparable?superK,,VcomparingByKey(){return(,VSerializable)(c1,c2)-().compareTo(());}publicstaticK,VextsComparable?,VcomparingByValue(){return(,VSerializable)(c1,c2)-().compareTo(());}publicstaticK,,VcomparingByKey(Comparator?superKcmp){(cmp);return(,VSerializable)(c1,c2)-((),());}publicstaticK,,VcomparingByValue(Comparator?superVcmp){(cmp);return(,VSerializable)(c1,c2)-((),());}}//Comparisonandhashingbooleanequals(Objecto);inthashCode();defaultVgetOrDefault(Objectkey,VdefaultValue){Vv;return(((v=get(key))!=null)||containsKey(key))?v:defaultValue;}defaultvoidforEach(BiConsumer?superK,?superVaction){(action);for(,Ventry:entrySet()){Kk;Vv;try{k=();v=();}catch(IllegalStateExceptionise){//(ise);}(k,v);}}defaultvoidreplaceAll(BiFunction?superK,?superV,?extsVfunction){(function);for(,Ventry:entrySet()){Kk;Vv;try{k=();v=();}catch(IllegalStateExceptionise){//(ise);}//=(k,v);try{(v);}catch(IllegalStateExceptionise){//(ise);}}}defaultVputIfAbsent(Kkey,Vvalue){Vv=get(key);if(v==null){v=put(key,value);}returnv;}defaultbooleanremove(Objectkey,Objectvalue){ObjectcurValue=get(key);if(!(curValue,value)||(curValue==null!containsKey(key))){returnfalse;}remove(key);returntrue;}defaultbooleanreplace(Kkey,VoldValue,VnewValue){ObjectcurValue=get(key);if(!(curValue,oldValue)||(curValue==null!containsKey(key))){returnfalse;}put(key,newValue);returntrue;}defaultVreplace(Kkey,Vvalue){VcurValue;if(((curValue=get(key))!=null)||containsKey(key)){curValue=put(key,value);}returncurValue;}defaultVcomputeIfAbsent(Kkey,Function?superK,?extsVmappingFunction){(mappingFunction);Vv;if((v=get(key))==null){VnewValue;if((newValue=(key))!=null){put(key,newValue);returnnewValue;}}returnv;}defaultVcomputeIfPresent(Kkey,BiFunction?superK,?superV,?extsVremappingFunction){(remappingFunction);VoldValue;if((oldValue=get(key))!=null){VnewValue=(key,oldValue);if(newValue!=null){put(key,newValue);returnnewValue;}else{remove(key);returnnull;}}else{returnnull;}}defaultVcompute(Kkey,BiFunction?superK,?superV,?extsVremappingFunction){(remappingFunction);VoldValue=get(key);VnewValue=(key,oldValue);if(newValue==null){//deletemappingif(oldValue!=null||containsKey(key)){//somethingtoremoveremove(key);returnnull;}else{//;}}else{//addorreplaceoldmappingput(key,newValue);returnnewValue;}}defaultVmerge(Kkey,Vvalue,BiFunction?superV,?superV,?extsVremappingFunction){(remappingFunction);(value);VoldValue=get(key);VnewValue=(oldValue==null)?value:(oldValue,value);if(newValue==null){remove(key);}else{put(key,newValue);}returnnewValue;}}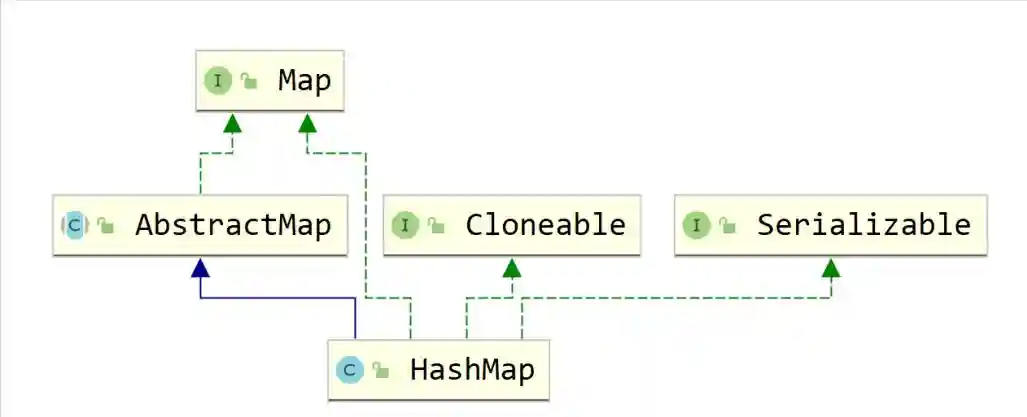
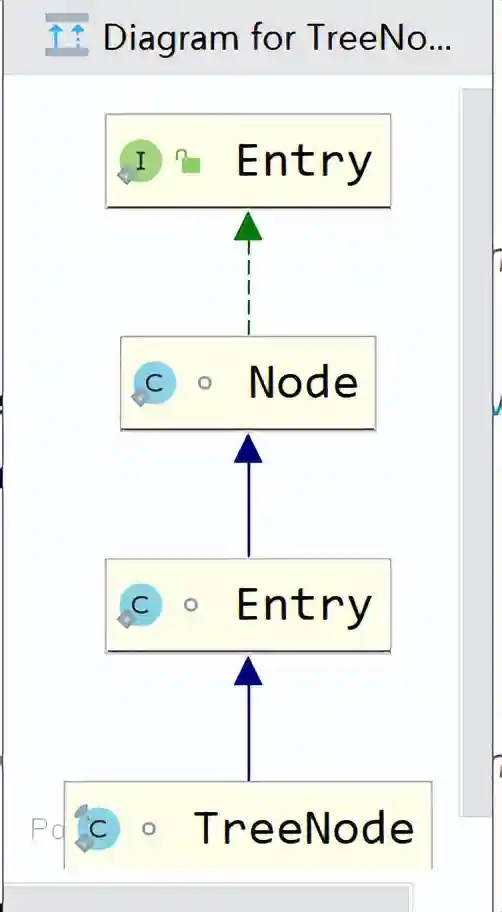
transientNodeK,V[]table;

//是hashMap的最小容量16,容量就是数组的大小也就是变量,transientNodeK,V[]table。staticfinalintDEFAULT_INITIAL_CAPACITY=14;//aka16//最大数量,该数组最大值为2^31一次方。staticfinalintMAXIMUM_CAPACITY=130;//默认的加载因子,如果构造的时候不传则为0.75staticfinalfloatDEFAULT_LOAD_FACTOR=0.75f;//一个位置里存放的节点转化成树的阈值,也就是8,比如数组里有一个node,这个//node链表的长度达到该值才会转化为红黑树。staticfinalintTREEIFY_THRESHOLD=8;//当一个反树化的阈值,当这个node长度减少到该值就会从树转化成链表staticfinalintUNTREEIFY_THRESHOLD=6;//满足节点变成树的另一个条件,就是存放node的数组长度要达到64staticfinalintMIN_TREEIFY_CAPACITY=64;//具体存放数据的数组transientNodeK,V[]table;//entrySet,一个存放k-v缓冲区,VentrySet;//size是指hashMap中存放了多少个键值对transientintsize;//对map的修改次数transientintmodCount;//加载因子finalfloatloadFactor;
//只有容量,initialCapacitypublicHashMap(intinitialCapacity){this(initialCapacity,DEFAULT_LOAD_FACTOR);}publicHashMap(){=DEFAULT_LOAD_FACTOR;//allotherfieldsdefaulted}publicHashMap(Map?extsK,?extsVm){=DEFAULT_LOAD_FACTOR;putMapEntries(m,false);}finalvoidputMapEntries(Map?extsK,?extsVm,booleanevict){ints=();if(s0){if(table==null){//pre-sizefloatft=((float)s/loadFactor)+1.0F;intt=((ft(float)MAXIMUM_CAPACITY)?(int)ft:MAXIMUM_CAPACITY);if(tthreshold)threshold=tableSizeFor(t);}elseif(sthreshold)resize();for(?extsK,?extsVe:()){Kkey=();Vvalue=();putVal(hash(key),key,value,false,evict);}}}publicHashMap(intinitialCapacity,floatloadFactor){if(initialCapacity0)//容量不能为负数thrownewIllegalArgumentException("Illegalinitialcapacity:"+initialCapacity);//当容量大于2^31就取最大值131;if(initialCapacityMAXIMUM_CAPACITY)initialCapacity=MAXIMUM_CAPACITY;if(loadFactor=0||(loadFactor))thrownewIllegalArgumentException("Illegalloadfactor:"+loadFactor);=loadFactor;//当前数组table的大小,一定是是2的幂次方//tableSizeFor保证了数组一定是是2的幂次方,是大于initialCapacity最结进的值。=tableSizeFor(initialCapacity);}tableSizeFor()方法保证了数组大小一定是是2的幂次方,是如何实现的呢?staticfinalinttableSizeFor(intcap){intn=cap-1;n|=n1;n|=n2;n|=n4;n|=n8;n|=n16;return(n0)?1:(n=MAXIMUM_CAPACITY)?MAXIMUM_CAPACITY:n+1;}publicVput(Kkey,Vvalue){returnputVal(hash(key),key,value,false,true);}finalVputVal(inthash,Kkey,Vvalue,booleanonlyIfAbsent,booleanevict){NodeK,V[]tab;NodeK,Vp;intn,i;if((tab=table)==null||(n=)==0)n=(tab=resize()).length;//当hash到的位置,该位置为null的时候,存放一个新node放入//这儿p赋值成了table该位置的node值if((p=tab[i=(n-1)hash])==null)tab[i]=newNode(hash,key,value,null);else{NodeK,Ve;Kk;//该位置第一个就是查找到的值,将p赋给eif(==hash((k=)==key||(key!=(k))))e=p;//如果是红黑树,调用红黑树的putTreeVal方法elseif(pinstanceofTreeNode)e=((TreeNodeK,V)p).putTreeVal(this,tab,hash,key,value);else{//是链表,遍历,注意e=这个一直将下一节点赋值给e,直到尾部,注意开头是++binCountfor(intbinCount=0;;++binCount){if((e=)==null){=newNode(hash,key,value,null);//当链表长度大于等于7,插入第8位,树化if(binCount=TREEIFY_THRESHOLD-1)//-1for1sttreeifyBin(tab,hash);break;}if(==hash((k=)==key||(key!=(k))))break;p=e;}}if(e!=null){//existingmappingforkeyVoldValue=;if(!onlyIfAbsent||oldValue==null)=value;afterNodeAccess(e);returnoldValue;}}++modCount;if(++sizethreshold)resize();afterNodeInsertion(evict);returnnull;}finalNodeK,VgetNode(inthash,Objectkey){NodeK,V[]tab;NodeK,Vfirst,e;intn;Kk;//先判断表不为空if((tab=table)!=null(n=)0//这一行是找到要查询的Key在table中的位置,table是存放HashMap中每一个Node的数组。(first=tab[(n-1)hash])!=null){//Node可能是一个链表或者树,先判断根节点是否是要查询的key,就是根节点,方便后续遍历Node写法并且//对于只有根节点的Node直接判断if(==hash//alwayscheckfirstnode((k=)==key||(key!=(k))))returnfirst;//有子节点if((e=)!=null){//红黑树查找if(firstinstanceofTreeNode)return((TreeNodeK,V)first).getTreeNode(hash,key);do{//链表查找if(==hash((k=)==key||(key!=(k))))returne;}//遍历链表,当链表后续为null则推出循环while((e=)!=null);}}returnnull;}5.3HashTable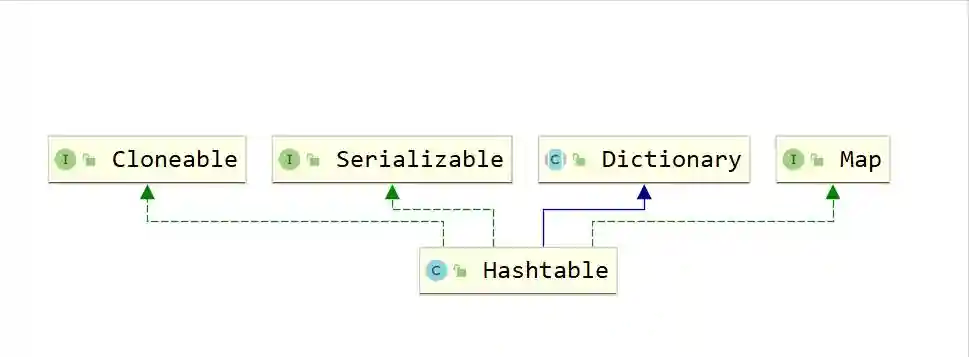
publicabstractclassDictionaryK,V{publicDictionary(){}publicabstractintsize();publicabstractbooleanisEmpty();publicabstractEnumerationKkeys();publicabstractEnumerationVelements();publicabstractVget(Objectkey);publicabstractVput(Kkey,Vvalue);publicabstractVremove(Objectkey);}//throwsNullPointerExceptionifthe{@codekey}is{@codenull}./***Thehashtabledata.*真正存放数据的数组*/privatetransientEntry?,?[]table;/***Thetotalnumberofentriesinthehashtable.*/privatetransientintcount;/***Thetableisrehashedwhenitssizeexceedsthisthreshold.(The*valueofthisfieldis(int)(capacity*loadFactor).)*重新hash的阈值*@serial*/privateintthreshold;/***Theloadfactorforthehashtable.*@serial*/privatefloatloadFactor;
finalinthash;finalKkey;Vvalue;EntryK,Vnext;
publicsynchronizedVput(Kkey,Vvalue){//Makesurethevalueisnotnullif(value==null){thrownewNullPointerException();}//?,?tab[]=table;inthash=();//在数组中的位置0x7fffffff是31位二进制1intindex=(hash0x7FFFFFFF)%;@SuppressWarnings("unchecked")EntryK,Ventry=(EntryK,V)tab[index];for(;entry!=null;entry=){//如果遍历链表找到了则替换旧值并返回if((==hash)(key)){Vold=;=value;returnold;}}addEntry(hash,key,value,index);returnnull;}privatevoidaddEntry(inthash,Kkey,Vvalue,intindex){Entry?,?tab[]=table;//如果扩容需要重新计算hash,所以index和table都会被修改if(count=threshold){//Rehashthetableifthethresholdisexceededrehash();tab=table;hash=();index=(hash0x7FFFFFFF)%;}//Createsthenewentry.@SuppressWarnings("unchecked")EntryK,Ve=(EntryK,V)tab[index];//插入新元素tab[index]=newEntry(hash,key,value,e);count++;modCount++;}tab[index]=newEntry(hash,key,value,e);@SuppressWarnings("unchecked")publicsynchronizedVget(Objectkey){Entry?,?tab[]=table;inthash=();intindex=(hash0x7FFFFFFF)%;for(Entry?,?e=tab[index];e!=null;e=){if((==hash)(key)){return(V);}}returnnull;}
- 最近发表
- 随机阅读
-
- Hollywood·人物琼·克劳馥——好莱坞黄金时期的“女流氓”
- 中国教育考试网中小学教师资格考试网报官网 2019教师资格证报名入口
- 正式入驻国际网球名人堂:李娜,我们为有你而骄傲
- 交易所第一届上市委首次“上岗”,3家首发企业均过会
- Nov 1 双语新闻精选:川普欲废除‘出生公民权’ Trump targets US citizenship
- 炉石传说:新版本迄今为止最强沉默?能否让牧师走出下水道
- 妈妈我爱你,你也爱我(欢快感人的英文歌曲动画)
- 考研报名入口官网?报名条件?
- 襄阳公布人事任免名单
- 调查显示:新加坡本地华族青年使用华语英语信心相近
- 阅读《瓦尔登湖》中有许多经典金句
- 中保协首次发布财产再保险比例及非比例合同范本中文版
- 从进博会之窗看中国对外开放新格局
- 中国龙 Dragon改为Loong,日本天皇改日皇?还有哪些需要改呢?
- 让男人深爱到入骨的女人:“任性”
- 1月4日周六早上好问候群友:愿平安与幸福相伴左右,幸福永远相随
- 浅析18-19世纪,欧洲美术展览展品类型,对现代艺术展览有何启发
- 部编版语文三年级下册:语文园地二
- 9月29日,燕山大学理学院2023年研究生招生直播宣讲会准时开启!
- 作为一个姑娘,我为什么不喜欢小妞电影
- 猜你喜欢
-
- 搜索
-
- 友情链接
-